내용 목차
본 장에서는 Tibero Standby Cluster의 구성요소와 동작 및 운영 방법을 설명한다.
Tibero Standby Cluster는 데이터베이스의 고가용성, 데이터의 보호, 재난 복구 등을 목적으로 제공하는 Tibero의 핵심 기능이다.
Tibero Standby 서버는 물리적으로 독립된 장소에 원본 데이터베이스의 복사본을 트랜잭션 단위로 보관한다. 복사할 대상이 되는 원본 데이터베이스를 Primary DB(이하 Primary)라 하고, 복사된 데이터가 저장되는 데이터베이스를 Standby DB(이하 Standby)라고 한다.
Tibero Standby Cluster의 원리는 Primary에서 생성된 Redo 로그를 배경 프로세스가 Standby로 전송하고, Standby는 Redo 로그를 이용해 Primary의 모든 변화를 똑같이 반영하는 것이다.
다음은 Tibero Standby Cluster가 어떻게 동작하는지를 나타내는 그림이다.
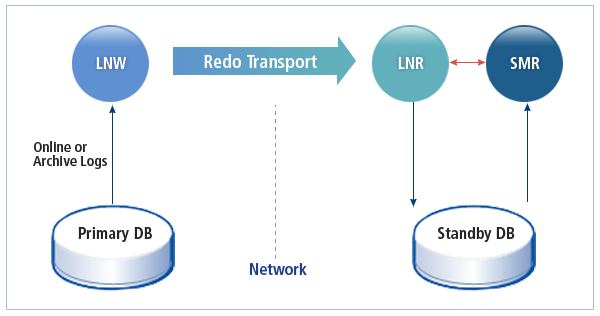
데이터의 복사를 통해 Primary는 서비스가 요청한 데이터 처리에 실패했을 경우 Standby의 데이터를 활용해 해당 서비스를 신속히 재개할 수 있다. 또한 Primary의 서버만으로는 손상된 데이터를 복구를 할 수 없는 경우에도 쉽게 대처할 수 있다.
예를 들면 Primary의 서버의 디스크가 손상된 경우 Standby를 통해 손상된 데이터를 보호할 수 있다.
Tibero Standby Cluster의 프로세스는 다음과 같다.
-
Primary의 Redo 로그를 Standby로 전송하는 프로세스이다. 로그 전송 방식과 무관하게 로그를 보내는 것은 항상 LNW에서 이루어진다. Standby는 9개까지 설정이 가능하며, 각 Standby마다 LNW가 하나씩 실행된다.
-
Standby에서 Primary로부터 받은 Redo 로그를 온라인 Redo 로그 파일에 기록하는 프로세스이다.
Standby는 MOUNT나 NORMAL이 아닌 RECOVERY 부트 모드로 동작하며 이때, log writer는 사용되지 않고, LNR이 LGWR의 역할을 대신한다. LNR은 RCWP 프로세스의 스레드 중 하나로 동작한다.
-
온라인 Redo 로그를 읽어 Standby에 적용하는 복구 과정을 수행하는 프로세스이다. SMR은 RCWP 프로세스의 스레드 중 하나로 동작한다.
다음은 Standby로 연결할 데이터베이스의 정보와 각 Standby의 종류 그리고 동작 모드를 설정하는 방법이다.
<<$TB_SID.tip>>
LOG_REPLICATION_MODE = {PROTECTION|AVAILABILITY|PERFORMANCE}
LOG_REPLICATION_DEST_1 = "hostname_1:port_1 {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"
LOG_REPLICATION_DEST_2 = "hostname_2:port_2 {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"
...
LOG_REPLICATION_DEST_N = "hostname_N:port_N {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"
다음은 위 파일에서 설정한 각 초기화 파라미터에 대한 설명이다.
-
-
데이터를 보호하는 수준에 중점을 둘지 또는 성능을 최대화할지에 대한 전체적인 동작 모드를 설정한다. 한 번만 설정하면 된다.
-
LOG_REPLICATION_MODE 초기화 파라미터에 설정할 수 있는 항목은 다음과 같다.
항목 설명 PROTECTION LGWR SYNC로 설정된 Standby가 하나도 없는 경우를 허용할 수 없는 항목이다. 이 항목을 설정하면 서버를 기동할 때 초기화 에러가 발생한다. 이 에러를 해결하기 위해서는 모드에 따라 Standby에 맞게 설정한 후 다시 서버를 기동해야 한다. AVAILABILITY PROTECTION 항목과 마찬가지로 LGWR SYNC로 설정된 Standby가 하나도 없는 경우를 허용할 수 없는 항목이다. 이 항목을 설정하면 서버를 기동할 때 초기화 에러가 발생한다. 이 에러를 해결하기 위해서는 모드에 따라 Standby에 맞게 설정한 후 다시 서버를 기동해야 한다. PERFORMANCE Standby로 로그가 전송되는 방식에 제한이 없고 동기화를 보장하지 않으므로 시스템 성능을 높이는 데 가장 유리한 항목이다.
-
-
-
각 Standby의 데이터베이스의 연결 정보(hostname:port)와 로그 전송 방식을 설정한다. 설정할 수 있는 최대 Standby의 개수(N)은 9이고, 필요한 만큼만 LOG_REPLICATION_DEST_1부터 설정한다.
-
연결 정보 중 포트 번호는 기본적으로 LISTENER_PORT+4 값으로 설정한다. 해당 값은 파라미터 설정을 통하여 변경할 수 있다.
-
LOG_REPLICATION_DEST_N 초기화 파라미터에 설정할 수 있는 항목은 다음과 같다.
항목 설명 LGWR SYNC LGWR SYNC로 설정된 Standby는 Primary의 Redo 버퍼의 내용을 전송받아 동작하므로 가장 빈번하게 Redo 로그를 전송한다. 따라서 데이터가 보호될 확률도 높다. 반면에 Primary의 성능 저하가 심하므로 Standby를 Primary와 비슷한 수준으로 구축할 것을 권장한다.
PERFORMANCE 모드와 같이 사용할 수 있는데 이러한 경우 데이터를 보호하지 못하더라도 Primary는 계속 진행할 수 있다. 따라서 Standby가 느리면 온라인 Redo 로그 파일이나 아카이브 로그 파일에서 Redo 로그를 읽어 전송할 수 있으므로 Primary를 ARCHIVELOG 모드로 운영할 것을 권장한다.
LGWR ASYNC LGWR ASYNC로 설정된 Standby는 LGWR SYNC와 ARCH ASYNC의 중간 수준의 빈도로 Redo 로그를 전송한다.
기본적으로 온라인 Redo 로그 파일을 읽어서 전송하지만 Standby가 따라오지 못하는 경우 아카이브 로그 파일에서 읽을 수도 있으므로 Primary를 ARCHIVELOG 모드로 운영할 것을 권장한다.
ARCH ASYNC ARCH ASYNC로 설정된 Standby가 하나 이상 존재하면 Primary는 반드시 ARCHIVELOG 모드로 동작해야 한다. 그렇지 않으면 서버의 기동은 정상적으로 되지만 해당 Standby는 아무런 동작도 하지 못하게 된다. 이 점을 주의해야 한다.
비록 ARCH ASYNC인 Standby를 사용하지 않더라도 Standby 기능을 사용할 때에는 Primary를 ARCHIVELOG 모드로 운영할 것을 권장한다.
-
-
-
Primary DB down 없이 동적으로 Standby를 추가할 수 있는 파라미터다. 아래와 같은 SQL 문을 이용하여 운영 중 Standby를 추가할 수 있다.
sql> alter system set LOG_REPLICATION_MODE={PROTECTION|AVAILABILITY|PERFORMANCE} sql> alter system set LOG_REPLICATION_DEST_1 = "hostname_1:port_1 {LGWR SYNC|LGWR ASYNC|ARCH ASYNC}" sql> alter system set LOG_REPLICATION_1_ENABLE=Y; (N으로 설정하면 동기화 모드 비활성화)
주의
동적으로 추가하고자 하는 DEST의 Index는 반드시 순서를 지켜야 한다. 예를 들어 DEST_1 설정 없이 DEST_5를 설정하려고 할 경우 DDL이 실패한다.
-
Primary를 NORMAL 모드로 기동하면 $TB_SID.tip 파일에 설정된 각 Standby와 연결이 이루어지고, 배경 프로세스에 의해 자동으로 데이터 이중화(Replication)가 이루어진다. 예를 들어 PROTECTION이나 AVAILABILITY 동작 모드로 기동하고 LGWR SYNC인 Standby가 모두 연결이 불가능한 상태라면 Primary도 운영이 불가능하므로 반드시 Standby를 먼저 기동해야 한다. 그 외의 경우에는 Standby를 나중에 기동하더라도 자동으로 연결되므로 운영이 가능하다.
참고
Primary에서 데이터베이스를 생성하는 동안에는 $TB_SID.tip 파일에 있는 Standby 설정이 무시된다. 따라서 Primary에서 생성된 DB 파일을 DBA가 수동으로 Standby로 복사해야 한다.
Standby를 운영하기 위해 필요한 설정 과정은 다음과 같다.
-
Primary에서 백업한 DB 파일을 복사해서 Standby를 구성한다.
컨트롤 파일, 온라인 로그 파일, 패스워드 파일을 포함한 모든 데이터 파일을 복사한다. 패스워드 파일을 함께 복사하는 이유는 Primary가 Standby에 SYS 권한을 가지고 접속하므로 SYS의 패스워드가 서로 일치해야 하기 때문이다.
-
Standby의 $TB_SID.tip 파일을 열어 DB_NAME이 Primary와 같도록 수정한다.
-
$TB_SID.tip 파일에서 컨트롤 파일이 위치하는 디렉터리 경로가 1번에서 Primary 파일을 복사한 경로와 일치하는지 확인한다. 또한
DB_BLOCK_SIZE도 Primary에 설정된 것과 같아야 한다. 설정이 같으면 복사한 데이터 파일을 열 수 있다.Primary의 백업을 가져다 놓은 Standby의 디렉터리의 경로가 원래와 달라진 경우에는 Standby의 $TB_SID.tip 파일에 다음과 같이 경로 변환을 위한 정보를 추가해야 한다.
Primary와 Standby의 절대 경로는 각각 Primary와 Standby의 instance 디렉터리의 절대 경로이다.
-
Standby를 MOUNT 모드로 기동한 후 다음의 DDL 문장을 수행하면 해당 DB를 Standby로 설정하고, 변환된 경로가 컨트롤 파일에 적용된다.
경로가 다른데도 위의 과정을 수행하지 않고 Standby를 기동하는 경우 컨트롤 파일에 적힌 경로에 데이터 파일을 열 수 없다는 에러가 발생한다.
-
Standby를 운영하기 위한 설정을 완료하면 다음의 명령을 통해 DB가 Standby로 동작하도록 기동시킨다.
NORMAL 모드로 Standby를 한 번이라도 기동하게 되면 더 이상 Standby로서의 기능은 할 수 없고, 앞서 설명한 과정을 다시 반복하여 Standby를 설정해야 한다는 점에 주의한다.
Standby가 기동하기 전에 DB 파일이 이전의 버전이라 하더라도 일관성만 유지한다면 동작에는 문제가 없다. 내부적으로 Primary가 접속하여 Primary와 Standby 사이의 로그 갭(log gap)을 자동으로 맞춰 동작한다. 하지만 이 과정이 모두 Redo 로그에 의존하므로 두 DB 사이의 차이가 크고, Primary가 ARCHIVELOG 모드가 아니라면 필요한 Redo 로그가 존재하지 않아 동작이 불가능할 수 있다. 따라서 Primary는 ARCHIVELOG 모드로 동작시키거나 최근에 백업한 Primary를 Standby로 복사하여 두 DB의 DB 파일을 맞춘 후에 Primary를 동작시키는 것이 바람직하다.
Standby는 내부적으로 Primary로부터 받은 Redo 로그를 디스크에 기록하고, 이를 복구하여 데이터 파일에도 반영하는 일을 수행하는 RECOVERY 모드로 동작하기 때문에 DB에 사용자의 접근이 제한된다.
Standby를 read only 클러스터용으로 사용하는 경우와 같이 Standby에서 Redo 로그를 반영하는 과정을 중단하지 않고 읽기 작업을 원하는 경우가 있다. 그 때에는 다음의 DDL 문장을 실행하면 Standby는 복구 과정을 멈추지 않고 read only 세션을 허용한다.
Standby가 LGWR SYNC 모드로 설정되어 Primary와 동기화되어 있는 경우라면 Primary에 접속한 경우와 같이 최근에 커밋된 내용을 Standby에서도 볼 수 있다. 이 상태에서는 비록 DB 서버가 read only 모드임에도 불구하고 데이터의 내용이 변경될 수 있다는 사실에 주의해야 한다.
Standby를 다시 RECOVERY 모드로 전환시킬 때는 다음의 DDL 문장을 수행한다. 단, 연결 된 세션이 있다면 세션 작업이 끝날 때까지 기다린 후 RECOVERY 모드로 전환된다.
세션 작업이 끝날 때까지 기다리지 않고 바로 RECOVERY 모드로 전환해야 될 경우 다음의 DDL 문장을 수행한다. 다음의 DDL은 연결 된 모든 세션을 강제로 중지시킨 후 RECOVERY 모드로 전환한다.
Primary가 Single이 아니라 TAC일 때도 Standby를 운용할 수 있다.
다음은 TAC-TSC를 구성하는 절차이다.
-
TAC-TSC를 구성하기 위해선 Standby도 TAC 구성이어야 한다. 단, Standby에서 복구는 한 노드에서 진행되므로 Standby 쪽은 1-node TAC로 구성한다. TAC 구성 방법은 “14.6. TAC 구성”을 참고한다.
-
Primary 모든 노드의 $TB_SID.tip 파일에 LOG_REPLICATION_MODE와 LOG_REPLICATION_DEST_N 파라미터를 설정한다. 가급적이면 모든 노드에 대해 동일하게 설정해 주는 것을 권장한다.
-
“13.5. Standby 설정 및 운용”과 마찬가지로 Primary에서 백업한 DB 파일로 Standby를 구성하고, DB_NAME 수정, 파일 경로 변환 등을 수행한 후 기동한다.
TAC-TSC 구성에서 Primary 쪽에 다운되어 있는 노드가 있다면 Standby 노드는 해당 노드의 Redo 로그를 전송받지 못하고, 복구를 정상적으로 수행할 수 없다. Primary 쪽에서 아래의 파라미터를 활성화시켜주면 Primary의 다른 노드가 다운되어있는 노드의 Redo 로그를 대신 전송해주어 Standby 쪽에서 복구가 정상적으로 수행될 수 있다. Primary 노드가 일부 다운된 상황에서도 동기화를 이어가고 싶다면 필수적으로 설정해주어야 한다.
<<$TB_SID.tip>>
STANDBY_ENABLE_LOG_RECOVERY=Y
이렇게 다운된 노드의 로그를 대신 전송해주는 방식을 LGWR PROXY라고 하며, 위의 파라미터를 적용한 채 Primary를 기동하면 기본적으로 생성되어 있는 LGWR PROXY LNW들 중 자기 자신을 제외한 노드 개수 만큼의 LNW가 할당된다. 한 노드에서 최대 9개의 LNW가 가능하기 때문에 2-node TAC-TSC 구성에서는 8개의 LGWR PROXY LNW가 생성되고, 그 중 하나가 할당된다. Primary 중 한 노드가 다운되면 다른 노드에서는 다운된 노드에 대한 LGWR PROXY LNW의 상태가 CONNECTED로 바뀌고, 다운된 노드의 로그를 대신 전송해준다.
SQL> select * from v$standby_dest;
STANDBY_ADDR
--------------------------------------------------------------------------------
TYPE THREAD# FLAGS SENT_SEQ
---------------- ---------- -------------------------------- ----------
SENT_BLKNO ACKED_SEQ ACKED_BLKNO DELAY
---------- ---------- ----------- ----------
127.0.0.1:11004
LGWR ASYNC 0 CONNECTED 11
894 11 894 0
127.0.0.1:11004
LGWR PROXY 1 CONNECTED 7
880 7 880 0
Not Assigned:0
LGWR PROXY 65535 NOT CONNECTED -1
-1 -1 -1 0
(중략)
Not Assigned:0
LGWR PROXY 65535 NOT CONNECTED -1
-1 -1 -1 0
9 rows selected.
위의 파라미터를 사용할 때 로그 전송 방식이 ASYNC 모드일 경우 다운된 노드의 아카이브 로그를 대신 읽어야 할 경우가 생길 수 있다. 이를 위해선 Primary 각 노드의 LOG_ARCHIVE_DEST가 동일한 위치로 설정되어 있어야 한다. 하지만 일반적인 공유 디스크 환경에서는 이것이 불가능하므로 TAS를 사용해야 한다. TAS-TAC-TSC를 구성하는 방법은 TASCMD 의 cptolocal, cpfromlocal 명령어를 사용하여 Cold Backup을 이용해 구축하는 방법과 tbrmgr의 --for-standby 옵션을 사용해 Hot Backup으로 구축하는 방법이 있다.
참고
STANDBY_ENABLE_LOG_RECOVERY=Y일 경우 '설정된 DEST의 수'에 'TAC의 노드 수'를 곱한 값이 9를 초과하면 안된다.
멀티노드 TSC
TAC-TSC 구성에서 Standby는 TAC이지만 기본적으로 복구를 담당하는 노드 하나만 부팅이 가능하다. 하지만 Standby를 read only 모드로 사용하고자 할 때 한 노드가 복구와 사용자의 쿼리를 동시에 처리해야 하기 때문에 성능의 저하가 생길 수 있다.
멀티노드 TSC 기능은 TAC-TSC 구성에서 최대 Primary의 노드 개수만큼 Standby 노드를 부팅시킬 수 있는 기능이다.
Standby 쪽에 TAC를 구성 후 Standby 모든 노드의 $TB_SID.tip 파일에 아래 파라미터를 설정해주면 멀티노드 TSC 기능이 활성화된다. 멀티노드 TSC를 구성하는 경우 Primary와 마찬가지로 Standby 각 노드에는 고유의 Redo 스레드가 할당되어야 한다.
<<$TB_SID.tip>>
STANDBY_ENABLE_TAC_MULTINODE=Y
멀티노드 TSC 기능을 사용하면 복구를 담당하는 노드 외에 추가적으로 read only 모드로 동작 가능한 Standby 노드를 부팅시킬 수 있다. 추가로 부팅된 read only 노드를 이용하면 사용자의 쿼리 부하를 분산시킬 수 있어 복구 및 쿼리의 성능이 향상되는 효과를 기대할 수 있다.
Standby에서 복구를 담당하는 노드는 Primary의 $TB_SID.tip 파일에서 설정된 노드이며, 복구는 한 노드가 담당하므로 모든 Primary의 $TB_SID.tip 파일에 동일하게 설정되어 있어야 한다.
Primary를 재기동하지 않고 복구를 담당하는 노드를 바꾸고 싶다면 Primary 모든 노드에서 아래의 sql을 수행해주면 된다. 단, Primary 각 노드에 설정된 LOG_REPLICATION_DEST가 다른 상황은 허용되지 않으므로 모든 노드의 연결 정보를 수정한 후에 동기화를 활성화해야 한다.
sql> alter sysetm set LOG_REPLICATION_1_ENABLE=N; (동기화 비활성화)
sql> alter system set LOG_REPLICATION_DEST_1 = "hostname_1:port_1
{LGWR SYNC|LGWR ASYNC|ARCH ASYNC}"; (연결 정보 수정)
sql> alter system set LOG_REPLICATION_1_ENABLE=Y; (바꾼 설정으로 동기화 활성화)
참고
멀티노드 TSC 기능을 사용하는 Standby는 RECOVERY 모드로 부팅 시 READONLY 모드로 전환되고, RECOVERY 모드로 변경될 수 없다. 따라서 아래의 DDL은 멀티노드 TSC 기능을 사용하는 Standby에서는 수행이 제한된다.
alter database standby; alter database standby immediate;
본 절에서는 Standby를 Primary로 전환하는 과정을 두 가지 시나리오로 나누어 설명한다.
Primary를 Switchover 모드로 종료하고 Standby 중 하나를 Primary로 전환하려면 다음의 절차를 수행한다.
-
Primary에서 다음의 명령어를 입력한다.
Switchover 모드로 종료할 경우 NORMAL 모드와 동일하게 작동을 하며, 추가적으로 Primary에서 생성된 모든 Redo 로그를 Standby에 전송을 한뒤 종료하게 된다.
-
Standby 중 하나를 종료한 후 Failover 모드로 기동하면 그 DB가 새로운 Primary가 된다.
이전의 Primary를 새로운 Standby로 사용하고 싶다면 새로 Primary가 될 DB의 $TB_SID.tip 파일에
Standby(LOG_REPLICATION_MODE,
LOG_REPLICATION_DEST_n 초기화 파라미터)를 설정하고, 이전 Primary를
RECOVERY 모드로 기동한 후에 새로 Primary가 될 DB를 Failover 모드로 기동하면 서로 역할을 전환하여 수행할
수 있다. 이때 두 DB는 이미 동기화된 상태이므로 Standby를 구성할 때 필요한 새로운 Primary의 DB 파일을
복사하고, ALTER DATABASE Standby controlfile을 수행하는
과정은 더 이상 필요하지 않는다. 또한 새로운 Standby의 $TB_SID.tip 파일에 기존의 Standby와 관련된 설정이 남아 있더라도
DB가 NORMAL 모드로 운용될 때만 적용된다.
현재 Primary가 갑자기 비정상적으로 종료되었거나 접근이 불가능해진 경우 Standby 중 하나를 Primary로 사용할 수 있다. Standby를 Primary로 사용하기 위해서는 종료 후 다시 Failover 모드로 기동해야 한다. 만약 USE_STANDBY_REDO_LOG 기능을 사용하던 Standby가 Failover 모드 기동을 원할 경우 USE_STANDBY_REDO_LOG 파라미터를 유지한 상태에서 기동해야 한다.
참고
기존에 사용하던 Primary는 새로운 Primary가 운영된 후에는 더 이상 어떤 용도(Primary나 Standby)로도 Tibero Standby Cluster에 포함될 수 없다.
Primary와 Standby에 모두 접속하기 위해서는 tbdsn.tbr 파일에 각 DB의 접속 정보를 추가해야 한다.
예를 들면 다음과 같다.
<<tbdsn.tbr>>
PrimaryDB_SID=(
(INSTANCE=(HOST=primaryDB_hostname)
(PORT=primaryDB_port)
(DB_NAME=cluster_DB_NAME)
)
)
StandbyDB_SID=(
(INSTANCE=(HOST=StandbyDB_hostname)
(PORT=StandbyDB_port)
(DB_NAME=cluster_DB_NAME)
)
)
Primary와 Standby의 $TB_SID.tip 파일을 설정할 때 공통의 DB_NAME을 각각 SID 별로 설정해야 한다.
참고
Primary에서 장애가 발생하면 Standby에 자동으로 접속하는 방법이 있다. 이 방법에 대한 자세한 내용은 “Appendix A. tbdsn.tbr”를 참고한다.
Tibero에서는 Tibero Standby Cluster의 상태 정보를 제공하기 위해 다음 표에 나열된 동적 뷰를 제공하고 있다.
참고
동적 뷰에 대한 자세한 내용은 "Tibero 참조 안내서"를 참고한다.
Tibero Standby Cluster는 Primary에서 생성된 Redo 로그를 그대로 Standby에 전송하므로 서로 간의 컴퓨팅 환경(CPU bus size, endianness, OS 등)이 동일해야 하고, $TB_SID.tip 파일의 데이터베이스 블록의 크기도 동일해야 한다.
Redo 로그를 적용하는 Standby Cluster의 특성으로 데이터베이스 파일의 상태를 변경하는 DDL 중 일부는 허용하지 않는다. 이와 같은 연산은 Standby 없이 수행해야 한다. 즉, 데이터베이스를 백업하여 Standby에 적용해야 하는 제약이 있다.
다음은 Standby Cluster에서 지원하지 않는 작업들이다. 기존에는 로그가 남지 않는 DPL, DPI에 대해 지원하지 않았지만, 현재 Standby가 연결되어 있을 때 강제로 로깅을 하고 있다.
-
일부 데이터베이스 변경 DDL
ALTER DATABASE ADD LOGFILE ALTER DATABASE DROP LOGFILE ALTER DATABASE TEMPFILE ALTER DATABASE DATAFILE OFFLINE
-
JAVA EXTERNAL PROCEDURE 컴파일을 수행하는 DDL
CREATE OR REPLACE AND RESOLVE JAVA SOURCE CREATE OR REPLACE AND COMPILE JAVA SOURCE
참고
1. Standby가 Read only 모드일 경우 DB Link 기능은 사용할 수 없다.
2. Standby Cluster에서 암호화 테이블 스페이스를 사용하려면 Primary와 Standby의 보안 지갑 마스터 키가 같아야 한다. 즉, 한 쪽에서 생성된 보안지갑을 복사해서 써야 한다. 또한 Standby에서 보안 지갑이 열려있어야 한다.
TSC 는 다양한 추가 기능들을 제공한다.
로그 스위치가 발생하는 경우 재사용할 로그의 checkpoint 여부를 확인하지 않고 아카이빙 여부만 확인하고 덮어쓰는 standby 전용의 새로운 online log group이다.
backup set을 restore한 후 아래와 같은 절차로 이용할 수 있다.
-
초기화 파라미터 USE_STANDBY_REDO_LOG를 설정한다.
USE_STANDBY_REDO_LOG=Y
-
Standby Redo Log Group을 구성한다.
sql> alter database standby controlfile; sql> alter database add standby logfile thread 0 group 1 '/usr/tibero/log/stlog001.slf' size 100M; (size는 primary의 online log file과 일치하게 구성) sql> alter database add standby logfile thread 0 group 2 '/usr/tibero/log/stlog002.slf' size 100M; sql> alter database add standby logfile thread 0 group 3 '/usr/tibero/log/stlog003.slf' size 100M; sql> alter database add standby logfile thread 0 group 4 '/usr/tibero/log/stlog004.slf' size 100M; sql> alter database add standby logfile thread 0 group 5 '/usr/tibero/log/stlog005.slf' size 100M; sql> alter database add standby logfile thread 0 group 6 '/usr/tibero/log/stlog006.slf' size 100M; (개수는 자유롭게 설정 가능하나 Primary의 online로그 개수의 2배 권장) sql> alter database enable public standby redo thread 0; sql> alter database recover automatic for standby;
-
DB를 다운시킨 후 RECOVERY 모드로 부팅한다.
Snapshot Standby는 Primary와의 동기화는 계속 진행됨과 동시에 독자적으로 ddl/dml을 수행할 수 있는 Standby이다. 사용자는 자신이 원하는 시점에 Standby를 Snapshot Standby로 전환할 수 있으며, Snapshot Standby로 전환된 후 언제든지 다시 Standby로 전환할 수 있다. Snapshot Standby에서는 Redo 로그는 계속 동기화되지만, 받은 로그에 대한 SMR의 리커버리는 중단된다. Standby로 전환할 때 전환 후에 다시 Primary와의 동기화를 이어가기 위해서 Snapshot Standby로 전환된 후에 발생된 모든 변경 사항은 버려지고, DB는 처음 Snapshot Standby로 전환되었던 시점으로 돌아간다.
Standby는 독자적인 ddl/dml이 불가능한 데에 반해, Snapshot Standby는 독자적으로 ddl/dml을 수행할 수 있어 Standby를 테스트 용도로 사용할 수 있고, 그러면서도 Primary와의 동기화는 계속 유지되므로 DR로서의 본연의 역할도 수행할 수 있다.
Standby에서 Snapshot Standby로 전환하기 위한 절차는 다음과 같다.
-
초기화 파라미터 FLASHBACK_LOG_BUFFER와 USE_STANDBY_REDO_LOG를 설정한다. (“11.6.3. 플래시백 데이터베이스 실행 예제” 참고)
FLASHBACK_LOG_BUFFER=100M USE_STANDBY_REDO_LOG=Y
-
DB를 MOUNT 모드로 기동한다.
-
Standby Redo Log Group이 구성되어 있지 않다면 구성한다. (“13.11.1. Standby Redo Log Group” 참고)
sql> alter database add standby logfile thread 0 group 1 '/usr/tibero/log/stlog001.slf' size 100M; sql> alter database add standby logfile thread 0 group 2 '/usr/tibero/log/stlog002.slf' size 100M; sql> alter database add standby logfile thread 0 group 3 '/usr/tibero/log/stlog003.slf' size 100M; sql> alter database add standby logfile thread 0 group 4 '/usr/tibero/log/stlog004.slf' size 100M; sql> alter database add standby logfile thread 0 group 5 '/usr/tibero/log/stlog005.slf' size 100M; sql> alter database add standby logfile thread 0 group 6 '/usr/tibero/log/stlog006.slf' size 100M; sql> alter database enable public standby redo thread 0; sql> alter database recover automatic for standby;
-
플래시백 로그가 구성되어 있지 않다면 구성한다. (“11.6.3. 플래시백 데이터베이스 실행 예제” 참고)
sql> alter database add flashback logfile thread 0 group 1 '/usr/tibero/log/fblog001.fb' size 512M; sql> alter database add flashback logfile thread 0 group 1 '/usr/tibero/log/fblog002.fb' size 512M; sql> alter database add flashback logfile thread 0 group 1 '/usr/tibero/log/fblog003.fb' size 512M; sql> alter database enable public flashback thread 0;
-
Snapshot Standby로의 전환 ddl을 수행한다.
sql> alter database convert to snapshot standby;
-
DB를 RESETLOGS 모드로 기동한다.
Snapshot Standby에서 수행된 모든 ddl/dml의 변경 사항은 Redo 로그에 저장된다. 따라서 Primary로부터 받은 Redo 로그를 저장하기 위해선 Standby Redo Log Group 기능을 사용해야 한다. Standby Redo Log Group 기능에서는 로그 스위치의 경우 재사용할 로그 파일에 대한 checkpoint를 기다리지 않기 때문에 Primary로부터 계속 Redo 로그를 받아 놓을 수 있다.
Snapshot Standby를 다시 Standby로 전환한 후에는 SMR의 리커버리가 재개되어야 하는데, 이를 위해서는 SMR의 리커버리가 중단되었던 즉 Snapshot Standby로 전환되었던 시점으로 돌아가야 한다. Standby를 과거로 돌리기 위해 Flashback Database 기능이 사용되며, 이를 위해 플래시백 로그를 구성해야 한다. 또한 전환 ddl 수행 시 Snapshot Standby에서 수행될 변경 사항에 대한 플래시백 로깅이 활성화된다.
Snapshot Standby에서 Standby로 전환하기 위한 절차는 다음과 같다.
-
DB를 MOUNT 모드로 기동한다.
-
Standby로의 전환 ddl을 수행한다.
sql> alter database convert to standby;
-
초기화 파라미터 FLASHBACK_LOG_BUFFER를 제거한 후 DB를 RECOVERY 모드로 기동한다.
Standby로 돌아가기 위해 전환 ddl을 입력하면 플래시백 로깅이 비활성화되고 Snapshot Standby로 전환된 시점으로 플래시백이 이루어진다. 그 후 RECOVERY 모드로 부팅하면 SMR은 리커버리가 중단됐던 시점부터 그동안 Primary로부터 받아 놓았던 리두 로그를 리커버리한다. Snapshot Standby 상태였던 기간이 길었다면, Primary로부터 받아 놓았던 Redo 로그의 양이 많기 때문에 Primary의 상태를 따라 잡는 데 오래 걸릴 수 있다.
참고
Snapshot Standby 상태에서는 Failover가 불가능하다.
Primary에 여러 Standby 노드를 연결하면 Primary에게 부담이 될 수 있다. Cascading Standby를 이용하면 Primary가 모든 Standby 노드에게 redo 로그를 전송하지 않고, Primary 노드는 Cascading Standby 노드에만 Redo 로그를 전송, Cascading Standby 노드가 다른 Cascaded Standby 노드에게 Redo 로그를 전송하도록 해 Primary의 부담을 줄여준다.
Cascading Standby 기능을 사용하기 위해 STANDBY_ENABLE_CASCADING 파라미터를 설정한다. 그리고 Primary의 $TB_SID.tip 파일 설정과 동일하게 Cascading Standby 노드의 $TB_SID.tip 파일을 설정한다. Cascading Standby는 LOG_REPLICATION_MODE 중 AVAILABILTY와 PERFORMANCE만 지원하며 LOG_REPLICATION_DEST_N 중 LGWR ASYNC와 ARCH ASYNC만 지원한다.
<<$TB_SID.tip>>
STANDBY_ENABLE_CASCADING = Y
LOG_REPLICATION_MODE = {AVAILABILITY|PERFORMANCE}
LOG_REPLICATION_DEST_1 = "hostname_1:port_1 {LGWR ASYNC|ARCH ASYNC}"
LOG_REPLICATION_DEST_2 = "hostname_2:port_2 {LGWR ASYNC|ARCH ASYNC}"
...
LOG_REPLICATION_DEST_N = "hostname_N:port_N {LGWR ASYNC|ARCH ASYNC}"
주의
Cascading Standby 노드와 연결될 Cascaded Standby 노드를 구축할 때는 반드시 Cascading Standby 노드 구축 백업과 동일한 백업 혹은 이전의 백업을 이용해야 정합성에 문제가 없다.