내용 목차
본 장에서는 Parallel Execution의 기본개념과 동작원리를 소개하고 이를 유형별로 실행하는 방법을 설명한다.
Parallel Execution(이하 PE)은 한 개의 작업을 여러 개로 나누어 동시 처리를 실행하는 방법으로 데이터 웨어하우스(DW: Data Warehouse)와 BI(Business Information)를 지원하는 대용량 DB에서 발생하는 데이터 처리의 응답 시간을 획기적으로 줄일 수 있다. 또한 OLTP(On-Line Transaction Processing) 시스템에서도 배치 처리의 성능을 높일 수 있다.
PE는 시스템 리소스의 활용을 극대화하여 데이터베이스 성능을 향상시키고자 하는 것이 기본 사상이기 때문에 다음과 같은 작업에 대해 성능 향상을 기대할 수 있다.
-
대용량 테이블 또는 파티션 인덱스 스캔(partitioned index scan)이나 조인 등의 쿼리
-
대용량 테이블의 인덱스 생성
-
Bulk insert나 update, delete
-
Aggregations
PE가 시스템 리소스를 최대한 활용하는 방식인 만큼 잘못 사용했을 때는 리소스 고갈로 중요한 데이터 처리가 지연되거나 오히려 기대했던 성능이 나오지 못하는 경우가 발생할 수 있기 때문에 사용에 주의가 필요하다.
PE로 성능 향상을 기대할 수 있는 시스템 구성과 환경은 다음과 같다.
-
CPU, 클러스터링 등 시스템 측면의 Parallel 구성
-
충분한 입출력 대역폭
-
여유 있는 CPU 사용률(예: CPU 사용량이 30% 이하일 때)
-
정렬, 해싱 그리고 입출력 버퍼와 같은 작업을 수행하기 충분한 메모리
Degree of Parallelism(이하 DOP)이란 하나의 연산에 얼마나 많은 시스템 리소스를 할당하여 동시에 처리하도록 할 것인지를 결정하기 위해 사용되는 개념으로, 단순하게는 하나의 연산을 함께 수행하는 워킹 스레드(이하 WTHR)의 개수를 의미하기도 한다.
PE는 하나의 연산을 여러 개의 WTHR로 동시에 수행하도록 하는 intra-operation PE와 서로 다른 연산을 파이프 스트림(pipe stream) 방식으로 연결해 동시에 수행하도록 하는 inter-operation PE로 나눌 수 있다.
Tibero에서는 DOP 크기만큼의 WTHR를 할당하여 intra-operation PE를 구성하고 inter-operation PE에 대해서는 2-set을 구성하는 방식으로 최적의 PE를 수행한다. 따라서 PE의 실행 과정을 통제하는 Query Coordinator(이하 QC)는 PE를 위해 최대 2*DOP 개수만큼의 WTHR를 PE_SLAVE(Parallel Execution Slave)로 활용하게 된다. 단, 동시에 두 개 이상의 연산을 수행하는 inter-operation PE는 지원하지 않는다.
하나의 SQL 문장(쿼리)에서 하나의 DOP로 PE를 수행하며 한 쿼리에 여러 개의 Parallel Hint가 있거나, Parallel Hint가 있는 동시에 Parallel Option을 가진 테이블을 쿼리에 포함하는 경우 그 중 가장 큰 DOP를 그 쿼리의 DOP로 결정한다. 명시된 DOP가 0보다 작거나 같은 경우에는 디폴트 값 4로 DOP를 결정한다. DOP는 Parallel Hint에 명시할 수 있으며, 사용 방법은 "Tibero SQL 참조 안내서"를 참고한다.
DOP를 결정할 때 참고해야 할 요소는 다음과 같다.
-
시스템의 CPU 개수
-
시스템의 최대 프로세스 및 스레드 개수
-
테이블이 분산된 경우 그 테이블이 속해 있는 디스크의 개수
-
데이터의 위치나 쿼리의 종류
-
객체 파티션 개수
보통 한 사용자만 PE를 수행한다고 하면 정렬과 같은 CPU bound 작업은 CPU 개수의 1~2배로 DOP를 설정하는 것이 적당하고, 테이블 스캔과 같은 I/O bound 작업은 디스크 드라이브 개수의 1~2배로 DOP를 설정하는 것이 적당하다. 이처럼 쿼리의 종류와 시스템 환경을 고려하여 DOP를 설정하면 PE를 통해 더 나은 성능을 기대할 수 있다.
Tibero에서는 쿼리를 수행하는 과정에서 Parallel 연산을 수행할 차례가 되면 QC가 계산된 DOP 만큼의 WTHR를 요청하고, 이에 가용한 만큼의 WTHR를 PE_SLAVE로 얻어오게 된다.
다음과 같이 연산 하나로 수행하는 쿼리는 DOP 개수만큼 WTHR를 가져와서 하나의 연산을 담당할 하나의 PE_SLAVE set을 구성한다. 그 이외는 2*DOP 개수만큼 WTHR를 얻어오고 두 개의 PE_SLAVE set을 구성한다. 이때 WTHR의 개수가 사용자가 명시한 DOP로 수행하기에 부족하면 사용할 수 있는 WTHR만 가지고서 DOP를 재정의하여 수행하게 된다.
SELECT * FROM table1;
예를 들어 DOP를 4로 결정하여 힌트에 명시한 경우 2*DOP만큼의 WTHR가 필요한 상황이고 WTHR가 5개뿐이라면 DOP를 2로 재정의하고 4개의 WTHR를 얻어와 PE를 수행한다. 또는 사용 가능한 WTHR가 1개뿐이라면 Parallel Plan을 만들었더라도 차례로 수행한다. 즉, PE를 수행하지 않는다. 그리고 QC가 얻어온 PE_SLAVE는 쿼리 수행이 끝나면 다시 활용이 가능한 WTHR로 반환되며 다음 쿼리 수행을 위해 리소스를 점유하지 않는다.
Tibero에서는 Parallel Hint가 있거나 Parallel Option이 있는 테이블을 포함한 쿼리를 실행하면, Parallel Plan을 작성하게 된다. 이때 생성된 Parallel Plan의 수행 순서는 다음과 같다.
-
SQL을 수행하는 WTHR가 QC 역할을 담당한다.
-
parallel operator가 있으면 QC는 DOP에 따라 필요한 만큼의 WTHR를 PE_SLAVE로 얻어 온다.
-
PE 수행에 필요한 만큼의 WTHR가 확보되지 않으면 사용자에게 알리지 않고 내부에서 차례로 처리한다.
-
QC는 순서에 따라 연산이 2-set 구조를 기반으로 수행되도록 PE_SLAVE를 통제하는 역할을 담당한다.
-
쿼리 수행이 끝나면 QC는 PE_SLAVE에게서 취합한 쿼리 결과를 사용자에게 보내고, 작업을 종료한 PE_SLAVE를 다시 사용 가능한 WTHR로 반환한다.
PE는 QC가 생성한 실행 계획을 모든 PE_SLAVE가 공유하도록 구성되어 있으며 각 PE_SLAVE는 실행 계획의 특정 부분만을 실행하도록 QC가 메시지로 제어한다.
PE는 같은 부분의 실행 계획을 DOP 개수만큼의 PE_SLAVE로 나누어 수행하는 intra-parallelism을 지원한다. 이렇게 같은 연산을 수행하는 PE_SLAVE의 묶음을 PE_SLAVE set라고 한다. PE는 한 번에 최대 2개의 PE_SLAVE set을 구성함으로써 전체 실행 계획 중 서로 다른 두 개의 연산을 동시에 수행하는 inter-parallelism을 지원한다.
동시에 수행되는 PE_SLAVE set는 Producer set와 Consumer set으로 나뉜다.
다음은 2-set 구조와 Producer set, Consumer set를 설명하는 그림이다.
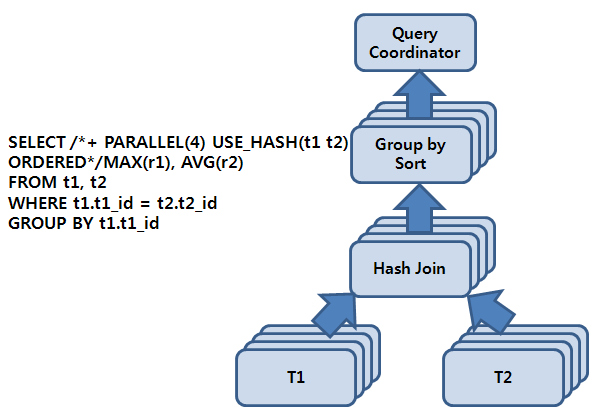
위 [그림 16.1]의 쿼리에서 Parallel Hint에 의해 DOP를 고려한 PE 실행 계획이 만들어지면 각각의 연산이 4개(최종으로 결정된 DOP)의 작업 단위로 분할된다. 다시 말해 각각의 PE가 4개의 스레드를 가지기 때문에 하나의 PE_SLAVE set이 4개의 PE_SLAVE로 구성되고, 이를 다시 Producer set와 Consumer set의 2-set 구조로 만들기 위해 총 8(= 2 x 4)개의 PE_SLAVE가 할당된다.
이때 할당된 2-set의 PE_SLAVE을 각각 set1, set2라고 하면 각 set가 수행하는 역할에 따라 Producer Set(Tibero Producer Set, 이하 TPS)와 Consumer Set(Tibero Consumer Set, 이하 TCS)로 전환되면서 전체 실행 계획이 수행된다. 즉, TCS가 해시 조인을 처리하기 위해 TPS가 T1 테이블에 스캔을 통해 로우를 공급해 주기를 기다리게 되며 TPS가 테이블 스캔을 시작함으로써 PE 실행 계획에 대한 작업이 시작된다.
set1이 TPS를 담당하여 T1을 스캔하고 set2가 TCS를 담당하여 set1이 보내는 로우에 대해 해시 테이블을 구성하게 되며, set1이 T1 스캔을 마치면 계속해서 T2 스캔을 수행하면서 TCS를 담당하는 set2에게 로우를 공급한다. set1이 T2의 스캔을 마치게 되면 TCS로 역할이 전환되면서 sort group by를 수행하게 되고, 반대로 set2는 TPS로 역할이 전환되면서 해시 조인의 결과를 set1에 공급한다. 마지막으로 set1이 TPS가 되어 sort group by 수행의 결과를 QC에게 보낸다.
이것이 2-set 구조를 이용하여 PE의 실행 계획에서 각각의 연산을 병렬로 수행하는 intra-operation parallelism을 수행하면서 동시에 다양한 연산을 교차하여 inter-operation parallelism을 수행하도록 하는 기본 동작 원리이다.
TPS는 TCS에 연산의 결과물을 공급하여 TCS가 다음 연산을 처리할 수 있도록 한다. TPS가 결과물을 분배하는데 Tibero는 hash, range, broadcast, round-robin, send idxm 5가지 방식을 지원하고 있다. 주로 hash, range, broadcast가 자주 사용된다.
| 분배방식 | 설명 |
|---|---|
| hash | TCS가 hash join, hash group by 등의 해시 기반의 연산을 담당하는 경우에 사용한다. send key의 hash value에 따라 해당 로우가 보내질 consumer 스레드가 정해진다. |
| range | TCS가 order by, sort group by와 같은 정렬 기반의 연산을 담당하는 경우에 사용한다. send key 값의 range에 따라 해당 로우가 보내질 consumer 스레드가 정해진다. |
| broadcast | Nested Loop 조인이나 pq_distribute 힌트를 사용하여 broadcast를 강제하는 조인을 TCS가 담당하는 경우에 사용한다. 자세한 내용은 “16.4.1. Parallel Query”를 참고한다. 모든 consumer 스레드에 로우가 보내진다. |
| round-robin | 로우를 보낼 consumer를 round-robin 방식으로 실행할 때 사용한다. |
| send idxm | Parallel DML에서 인덱스와 참조 제약조건을 위해 로우를 보낼 때 사용한다. |
본 절에서는 [그림 16.2]에서와 같이 range 방식을 예를 들어 설명한다.
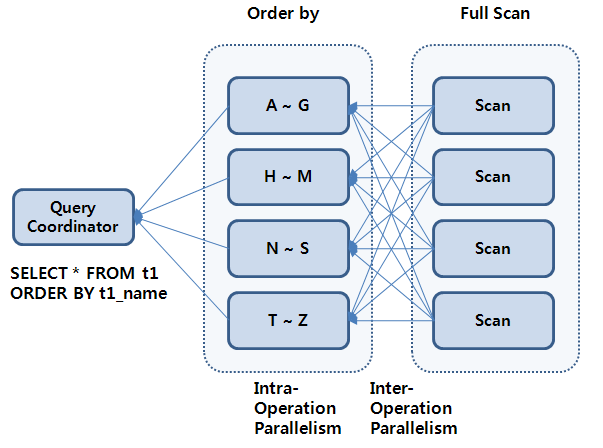
DOP가 4로 결정된 PE 실행 계획에서 inter-operation parallelism으로 TPS와 TCS 2개의 set가 상호 연동하는 방식을 선택하면 총 PE_SLAVE 8개가 전체 PE 수행에 참여하게 된다.
PE_SLAVE set 하나가 TPS가 되어 테이블 스캔을 하고 TCS로 설정된 다른 set가 order by를 수행할 수 있도록 로우를 공급해 준다. 이때 4개의 PE_SLAVE는 각각 A~G, H~M, N~S 그리고 T~Z로 정렬 키에 대한 범위를 정하여 정렬하게 되며, 이에 맞게 TPS는 range 방식으로 해당 로우가 담당하는 PE_SLAVE에 전달될 수 있도록 한다.
TCS가 정렬 작업을 완료하고 나면 TPS로 역할이 전환되면서 PE_SLAVE가 설정된 range의 순서대로 정렬 결과를 QC에게 전달함으로써 전체 데이터에 대한 결과가 얻어진다.
Tibero가 제공하는 parallel 연산은 다음과 같다.
-
액세스 방법
테이블 스캔 그리고 index fast full scan 등
-
조인 방법
Nested Loop, Sort Merge, 해시 조인
-
DDL
CREATE TABLE AS SELECT, CREATE INDEX, REBUILD INDEX, REBUILD INDEX PARTITION
-
DML
INSERT AS SELECT, UPDATE, DELETE
-
기타 연산
GROUP BY, ORDER BY, SELECT DISTINCT, UNION, UNION ALL, Aggregations
Parallel Hint가 사용되었거나 Parallel Option이 있는 테이블에 쿼리를 수행하면 Tibero는 Parallel Plan을 만들어 낸다. 단, Parallel로 수행하기 충분한 WTHR가 있을 때만 Parallel Plan대로 PE를 수행한다.
SQL> select /*+ parallel (3) */ * from t1; SQL> create table t1 (a number, b number) parallel 3; SQL> select * from t1;
Autotrace(explain plan)
Parallel Query에서는 Autotrace(explain plan)를 이용하여 Parallel Plan을 확인할 수 있다.
SQL> set autot on
select * from t1;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 PE BLOCK ITERATOR
4 TABLE ACCESS (FULL): T1
위의 실행 계획에서는 PE SEND와 PE RECV(또는 leaf 노드) 사이를 하나의 PE_SLAVE라고 볼 수 있으며 PE_SLAVE의 최상단에는 PE SEND가 있어 TPS인 경우 TCS에게 로우를 분배한다.
PE_SLAVE의 최하단에는 로우를 만드는 테이블 스캔(또는 index fast full scan) 연산자가 있거나 PE RECV가 있다. PE RECV는 PE_SLAVE가 TCS일 때 TPS가 분배하는 로우를 받아들인다.
예를 들면 다음과 같다.
SQL> select /*+ parallel (3) use_hash(t2) ordered */ * from t1, t2 where t1.a=t2.c; Explain Plan -------------------------------------------------------------------------------- 1 PE MANAGER 2 PE SEND QC (RANDOM) 3 HASH JOIN (BUFFERED 4 PE RECV 5 PE SEND (HASH) 6 PE BLOCK ITERATOR 7 TABLE ACCESS (FULL): T1 8 PE RECV 9 PE SEND (HASH) 10 PE BLOCK ITERATOR 11 TABLE ACCESS (FULL): T2
| 항목 | 설명 |
|---|---|
| PE MANAGER | PE를 시작하고 PE_SLAVE set을 coordination하는 연산이다. Serial Execution과 Parallel Execution 사이의 경계로 이 연산 아래부터는 Parallel로 수행된다. |
| PE SEND | producer slave가 로우를 분배하는 연산이다. PE_SLAVE 간의 분배 방법으로는 hash, range, broadcast, round-robin, send idxm이 있다. 자세한 내용은 “16.3.2. TPS 분배”를 참고한다. PE_SLAVE에서 QC로 로우를 보내는 방법은 다음과 같다.
|
| PE RECV | consumer slave에서 producer slave가 PE SEND를 통해 분배한 로우를 받아들이는 역할을 하는 연산이다. |
| PE BLOCK ITERATOR | 테이블 스캔, 인덱스 스캔에서 사용할 granule을 요청하고 받는 역할을 하는 연산이다. granule는 PE를 수행할 때 각 PE_SLAVE에 할당되는 일의 단위 크기로 크기를 어느 정도로 하느냐에 따라 PE의 성능에 영향을 미친다. |
| PE IDXM | Parallel DML에서 인덱스와 참조 제약조건을 하는 연산이다. |
Nested Loop
연산의 특성상 조인의 양쪽 child를 독립된 PES로 구분하지 않고 한쪽 child를 조인하는 PES와 합쳐 하나의 PES에서 수행되도록 하며, 반대편 child에서 PE SEND를 broadcast 방식으로 PE를 수행한다.
SQL> SELECT /*+parallel(3) use_nl(t1 t2) ordered*/ *
FROM t1, t2
WHERE a < c;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 NESTED LOOPS
4 BUFF
5 PE RECV
6 PE SEND (BROADCAST)
7 PE BLOCK ITERATOR
8 TABLE ACCESS (FULL): T1
9 PE BLOCK ITERATOR
10 TABLE ACCESS (FULL): T2
보통은 오른쪽 child를 조인 연산을 수행하는 slave에 포함시켜 수행하는 Parallel Plan을 만든다. 하지만 pq_distribute 힌트를 이용하여 어느 쪽 child를 합칠 것인지를 정하면 PE의 성능을 개선할 수 있다.
SQL> SELECT /*+parallel(3) pq_distribute(t2 broadcast none) use_nl(t2) ordered*/ *
FROM t1, t2
WHERE a=c;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 NESTED LOOPS
4 BUFF
5 PE RECV
6 PE SEND (BROADCAST)
7 PE BLOCK ITERATOR
8 TABLE ACCESS (FULL): T1
9 PE BLOCK ITERATOR
10 TABLE ACCESS (FULL): T2
SQL> SELECT /*+parallel(3) pq_distribute (t2 none broadcast) use_nl(t2) ordered*/ *
FROM t1, t2
WHERE a=c;
Explain Plan
--------------------------------------------------------------------------------
1 PE MANAGER
2 PE SEND QC (RANDOM)
3 NESTED LOOPS
4 PE BLOCK ITERATOR
5 TABLE ACCESS (FULL): T1
6 TABLE ACCESS (FULL): T2
제약 사항
다음의 연산은 Parallel로 수행하지 않는다.
-
rownum을 생성하는 연산
-
cube, rollup을 포함한 group by
-
분석 함수를 포함한 연산
-
top-N order by
예를 들면 다음과 같다.
SQL> SELECT * FROM (select * from t1 order by t1.a) WHERE rownum < 5; -
임시 테이블에 대한 테이블 스캔
-
dynamic performance view에 대한 스캔
-
외부 테이블에 대한 스캔
-
DBLink를 수행하는 연산
-
index range scan, index full scan, index skip scan, index unique scan
-
connect by
-
Tibero는 'create table ... as select, create index, rebuild index'를 Parallel로 수행할 수 있다.
'create table ... as select'는 의사 결정 지원 애플리케이션(decision support application)에서 요약 테이블을 만들 때 유용하게 사용할 수 있으며 select 부분과 insert 부분을 Parallel로 처리하여 보다 빠른 DDL의 수행을 기대할 수 있다.
DDL 문에 Parallel Option을 명시하는 방법으로 사용할 수 있으며 DDL과 관련된 문법은 "Tibero SQL 참조 안내서"를 참고한다.
Tibero는 insert, update, delete 문에 대해 Parallel DML을 지원하지만 'insert into ... values ...' 문의 Parallel DML은 지원하지 않는다. Parallel DML은 주로 큰 데이터를 insert, update, delete 처리하는 배치 작업에 유용하게 사용한다. 다시 말해 트랜잭션이 적은 작업에는 효과적이지 않다.
Enable Parallel DML
Parallel DML을 'alter session enable parallel dml'로 설정한 후 insert, update, delete 문 뒤에 Parallel Hint를 사용해야 DML을 Parallel로 수행한다. 'enable parallel dml'을 하지 않으면 DML 문에 힌트를 명시해도 Parallel로 수행하지 않는다. 즉, 'disable parallel dml'로 Parallel DML을 못하도록 설정할 수 있다.
Parallel DML은 DOP + 1 개의 트랜잭션으로 동작하며 커밋은 Two-phase commit으로 이루어진다. 롤백 또한 DML이 여러 개의 트랜잭션으로 이루어졌기 때문에 Parallel로 진행된다.
Parallel DML은 여러 개의 트랜잭션으로 진행되기 때문에 Parallel DML 후 커밋 이전까지는 같은 세션에서 select 문으로 해당 테이블을 조회할 수 없으며 Parallel DML로 수정된 테이블에 대한 조회는 커밋 후에 가능하다.
SQL> alter session enable parallel dml; SQL> insert /*+ parallel (3) */ into PE_test3 select * from PE_test3; 10001 rows created. SQL> select * from PE_test3; TBR-12066: Unable to read or modify an object after modifying it with PDML. SQL> insert /*+ parallel (3) */ into PE_test3 select * from PE_test3; TBR-12067: Unable to modify an object with PDML after modifying it.
insert
select 서브 쿼리에 Parallel Hint를 주어 insert뿐만 아니라 insert할 로우를 추출하는 select도 Parallel로 수행하여 더 빠르게 DML을 수행할 수 있다.
SQL> insert /*+ parallel (3) */ into PE_test3
select /*+ parallel (3) */ * from PE_test3;
10001 rows created.
제약 사항
다음의 경우는 Parallel DML로 수행하지 않는다.
-
insert into ... values ... 문인 경우
-
반환문이 있는 DML인 경우
-
Parallel DML로 수정된 테이블인 경우 커밋을 하기 전까지는 같은 세션에서 DML이나 쿼리로 접근할 수 없다.
-
트리거가 있는 테이블에 대한 DML인 경우
-
LOB 타입의 컬럼이 있는 테이블에 대한 DML인 경우
-
self reference, delete cascade 제약조건이 있는 DML인 경우
-
online rebuild 중인 인덱스를 갖는 테이블에 대한 DML인 경우
-
Standby가 있는 경우
Tibero가 제공하는 parallel 관련 뷰는 다음과 같다.